
Cet article de blog détaillé a pour vocation de présenter et étoffer l’impact de l’utilisation de JavaScript pour le référencement naturel (SEO). Il s’adresse aux équipes de développement et de design.
Spécialiste SEO et consultante, je remarque parfois la surprise des équipes de développement web et design au sujet des défis causés par JavaScript au niveau de l’optimisation pour les moteurs de recherche. Par cet article, j’espère faciliter leur compréhension et apporter des pistes d’optimisation. Cet article s’intéresse aux obstacles au crawling.
Bon à savoir: Cet article contient des anglicismes. Je trouve plus précis d’utiliser les mots en anglais, plutôt que d’utiliser des traductions françaises approximatives.
Pourquoi s’intéresser au Javascript en tant que consultante SEO?
En tant que SEO, l’analyse de JavaScript est extrêmement importante. Il est possible de signaler des difficultés à l’équipe de développement par quelques étapes d’analyse afin d’éviter des difficultés d’indexation.
Au niveau du SEO, deux défis principaux existent quant à l’utilisation de JavaScript:
- des obstacles au crawling. Rappel: pas d’indexation, pas de visibilité dans les résultats de recherche (SERP) = pas de possibilité de trafic organique,
- un temps de chargement des pages long, un manque de stabilité visuelle et une attente avant l’interactivité. Rappel: les Core Web Vitals impactent peuvent impacter le ranking d’un site web et l’expérience utilisateur.
Cet article s’intéresse au défi 1. L’indexation est un prérequis indispensable au trafic organique. Si une page ne peut pas être indexée, peu importe son score sur Lighthouse; optimiser les Core Web Vitals est inutile, il n’y aura pas d’impact sur le ranking.
Utiliser JavaScript pour des sites webs interactifs (interactive UI)
JavaScript constitue l’une des technologies de base du web. Alors que le HTML fournit la structure et que le CSS ajoute le style, JavaScript permet d’ajouter des contenus dynamiques tels que des menus déroulants, la validation de formulaires, des tuiles cliquables, des questions fréquentes en accordéons, etc. Contrairement à un langage côté serveur, comme Java ou PHP, JavaScript s’exécute sur le navigateur de l’utilisatrice et interagit directement avec la page web. S’il est question de design interactif (interactive design and interactive user interface), il est presque certain que le front-end utilisera du JavaScript.
Comment Google exécute-t-il JavaScript?
Google traite les applications Web JavaScript en trois phases principales :
- Exploration (crawling)
- Affichage (rendering)
- Indexation
Googlebot met les pages en file d’attente pour le crawling et le rendering. Une page peut être en attente de crawling ou en attente de rendering:
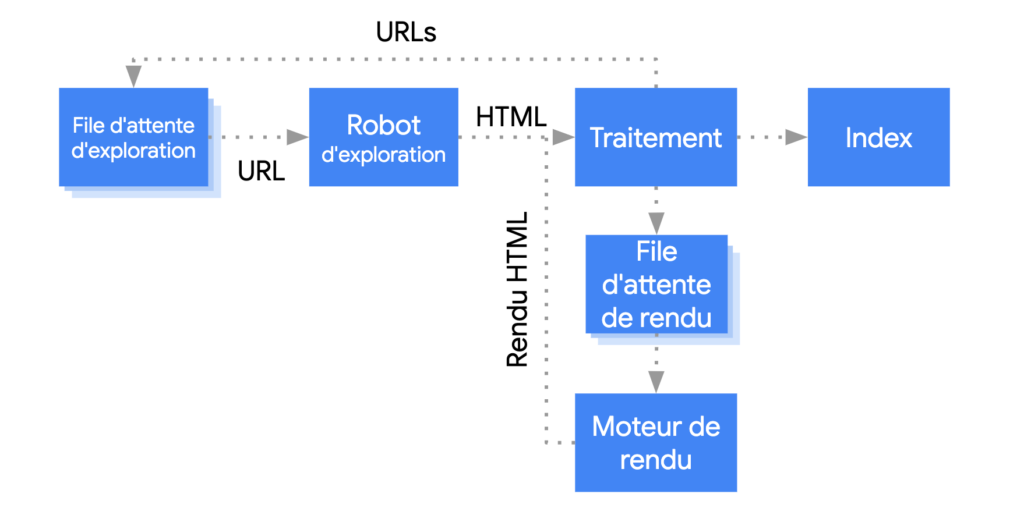
Crédit photo: Google Developers
{kind=link}
Le processus crawling-rendering est incontournable pour tous les sites internet et pour toutes les nouvelles pages. C’est à la spécialiste SEO de s’assurer que le contenu essentiel est compris des Google Bots. Mais pour ceci, la SEO a besoin de la collaboration des équipes des développement et de design.
“Pretty much every website when we see them for the first time goes to rendering, so there’s no indexing before it hasn’t been rendered.”
Impacts du robots txt et des attribut nofollow sur le processus d’indexation
Les robots crawlers de Google extraient une URL de la file d’attente via une requête HTTP et vérifient si le site internet autorise l’exploration. Si le fichier robots.txt, situé à la racine du site web empêche le crawling, Googlebot n’envoie pas la requête HTTP pour cette URL et ignore cette dernière. Il est possible d’empêcher le crawling d’un ou plusieurs robots, pour tout le site ou une section du site.
Après avoir vérifié l’autorisation de crawler cette URL via le robots.txt, Googlebot analyse la réponse pour les autres URLs inclus sur la page dans l’attribut href des liens HTML, puis ajoute ces autres URLs à la file d’attente du crawling. Pour empêcher la découverte de liens sur une page, il faut utiliser un attribut nofollow. On compare souvent les robots crawlers de Google à des araignées qui découvrent le web de lien en lien.
Le crawling d’une URL et l’analyse de la réponse HTML conviennent aux sites Web classiques ou aux pages affichées côté serveur dans lesquelles le code HTML de la réponse HTTP inclut tout le contenu. Certains sites JavaScript utilisent un modèle dans lequel le code HTML initial ne comporte pas le contenu réel du site internet. Dans ce cas, Google doit exécuter le JavaScript avant de pouvoir accéder au contenu de la page ou de la section sur la page générée par du JavaScript. Google compare alors la réponse initiale du serveur avec la page rendue (rendered).
La file d’attente pour le rendering peut être longue
Googlebot met toutes les pages en file d’attente pour le rendering, sauf si un en-tête ou une balise meta robots lui indique de ne pas indexer la page. La page peut rester dans cette file d’attente pendant quelques secondes ou plus longtemps. Une fois que les ressources de Google le permettent, le code JavaScript est exécuté. Ensuite, Google poursuit le processus: les liens dans le code HTML affiché/rendered sont mis en file d’attente pour l’exploration. Google utilise également le code HTML affiché/rendered pour indexer la page. Googlebot met en cache de manière agressive afin de réduire les requêtes réseau et l’utilisation des ressources. Le WRS (Web Rendering Service) peut ignorer les en-têtes de cache (source: Résoudre les problèmes JavaScript liés à la recherche). Si Google considère que le contenu n’est pas essentiel, il peut décider de ne pas récupérer ces ressources.
Les options de rendering
Le choix entre le rendering côté client et le rendering côté serveur est une décision importante en matière d’optimisation pour les moteurs de recherches que je recommande de prendre après avoir évalué l’impact potentiellement négatif.
Si vous lisez cet article et que vous travaillez dans une équipe de développement web, vous savez que le rendering est loin d’être simple.
En savoir plus au sujet du CSSOM et DOM trees qui se combinent pour former le render tree sur web.dev.
Pour ceux et celles qui n’en ont pas (encore) l’expérience au-delà du rendering côté serveur (server-side-rendering SSR), du rendering côté client (client side rendering-CSR) et du static rendering, il existe une variété d’options.

Crédit photo: Gray Dot Company training with Sitebulb and Women in Tech SEO
Globalement, le SSR coûte souvent plus cher à implémenter que le CSR, ce qui peut expliquer que le client side rendering est fréquent.
La meilleure solution pour les robots crawlers: server side rendering
Selon la documentation de Google, la méthode de rendering choisie n’a pas d’incidence sur le ranking, à condition que certaines règles soient respectées. Toutefois, Google affirme préférer le rendering côté serveur ou le pré-affichage puisqu’il permet aux utilisatrices comme aux robots crawlers d’accéder à votre site plus rapidement.
La difficulté d’un point de vue optimisation pour les moteurs de recherche
La difficulté d’un point de vue SEO se situe dans la différence du contenu avant et après le rendering. Un contenu non accessible/visible avant le rendering, donc d’un point de vue utilisation, avant une action humaine comme un clic, pourrait être qualifié de caché pour les utilisateurs et les robots crawlers. Mettre des éléments de contenu critiques accessibles uniquement après avoir exécuté du JavaScript revient à complexifier l’accès à ces informations et, potentiellement, perturber le processus de découverte et donc limiter une indexation optimale.
Recommandation de la Consultante SEO pour l’utilisation de JavaScript
Cet article vise à vous aider à avoir un esprit critique par rapport à l’utilisation de JavaScript et à vous aider à en évaluer ses avantages et les inconvénients. Je n’ai pas l’intention de vous convaincre d’arrêter complètement d’utiliser JavaScript. Toutefois, je suggère fortement d’éviter le JavaScript pour les informations critiques.
“Googlebot et son composant Web Rendering Service (WRS) analysent et identifient en permanence les ressources qui ne contribuent pas au contenu essentiel de la page et peuvent choisir de ne pas récupérer ces ressources.”
Je ne le dirai jamais assez: choisissez soigneusement les informations en JS et comment vous l’implémenter. Toutes les informations n’ont pas la même valeur en terme de SEO. Votre attention doit se porter premièrement sur les informations critiques, puis les moins critiques.
Bon à savoir: Le résumé des informations critiques est tiré de la formation Gray Dot, Sitebulb et WTS que vous trouvez en référence.
Les champs critiques
Les variations de langues ne doivent pas être gérées via du JS mais avoir des URLs propres.
Au niveaux du contenu, les éléments critiques sont:
- Title
- Metadescription (si utilisée)
- Meta robots
- Canonical tag
Les autres éléments importants sont:
- Les liens dans les menus (navigation)
- Les liens de pagination
- Les titres (h1, H2, H3 etc.)
Les nice to have des éléments critiques sont:
- le contenu textuel de la page (page copy)
- les liens dans le contenu style ‘anchor texts’
- les images qui apportent une information et text alternatif des images (ici je ne considère pas les images décoratives).
Les champs qui sont moins critiques
Au niveau du contenu, les champs suivants sont moins critiques:
- Contenu dupliqué
- Contenu trop centré sur la marque (non souhaité ou non efficace pour le SEO)
Au niveau des liens, les champs suivants sont moins critiques:
- Liens vers des pages avec accès restreint
- Liens vers des pages non indexables
Au niveau des médias, les champs suivants sont moins critiques:
- Images décoratives
- Images, vidéos, etc., qui ne sont pas essentielles au contenu de la page
Globalement, si un champ que je considère moins critique n’est pas découvert par les robots crawlers, je ne placerai pas d’activité liées à leur optimisation comme priorité dans le plan des tâches à réaliser.
Quels sont les indices qui indiquent qu’il y a un problème de Javascript?
Un des problèmes suivants indiquent une difficulté avec Javascript (liste non exhaustive):
- seule une partie de la page ou du contenu est crawlée ou indexée
- des images ne sont pas indexées
- des erreurs critiques qui empêchent le crawling/rendering: timeouts, problèmes d’accès aux scripts, cassés.
- les éléments SEO critiques ne figurent pas dans le code HTML de la réponse pour l’indexation de la première vague
- des métadonnées manquent
- les éléments SEO critiques sont modifiés entre la réponse et le rendered HTML
- les pages 404 ne fonctionnent pas, ou des erreurs Soft 404 inattendues
- des URL indésirables sont indexées : pages orphelines de « construction ».
Bon à savoir: Quand j’aurai un moment, j’écrirai un article comment découvrir et débugger des problèmes JS 🙂 En attendant, consultez la liste de sources de cet articles, vous trouverez de quoi vous former.
Conclusion
Il est probable que des expert-es aux compétences plus techniques lisent cet et disent : « La RSE ne pose pas de problème tant que vous faites {insérer une solution de contournement compliquée ici} ! ». Je comprends. Vous pouvez faire fonctionner la RSE. Mais le faire fonctionner est très différent d’opérer sur un cadre JS qui a des dépendances et des risques techniques minimaux. En particulier lorsque le référencement est à l’origine de la majorité des nouveaux contrats, la RSS est le choix le moins risqué et le plus rentable, selon mon opinion professionnelle.
Références et sources de cet article
Pour me former au JavaScript, j’ai consulté de nombreux articles et j’ai suivi des formations en ligne. Je remercie les personnes qui les ont créées. Vous trouverez ci-dessous les articles et les formations qui m’ont servi de sources pour cet article. Je vous recommande vivement de les consulter.
AHA! JavaScript SEO Moments: 8 Common JS SEO Issues & How to Overcome Them (Gray Dot Company, 2023)
Free JavaScript SEO Course: On-Demand Training, (Sitebulb, Women in Tech SEO, Gray Dot Company, 2024)
Comprendre les bases du SEO JavaScript (Google, documentation)
Le nouveau Googlebot, un robot à la page (Google, 2019)
The new evergreen Bingbot simplifying SEO by leveraging Microsoft Edge (Bing, 2019)
Évaluation de l’expérience sur la page pour améliorer le Web (Google,2020)
Google Webmaster Central office- hours (Google, 2019)