
This detailed blog post aims to explore the impact of JavaScript on search engine optimisation (SEO). It is intended for web development and design teams.
As an SEO specialist and consultant, I often notice that web development and design teams are surprised by the challenges JavaScript poses for SEO, particularly in terms of crawling and indexing. With this article, I aim to clarify those challenges and offer practical optimisation tips. This post focuses specifically on crawling obstacles.
Note: ChatGPT translated this article originally written in French. In case of doubt, go back to the French version or contact Isaline Muelhauser.
Why do SEOs care about JavaScript?
As an SEO consultant, analysing JavaScript is essential. By identifying potential issues through a few key analysis steps, it’s possible to flag challenges to the development team early on and avoid indexing problems.
When it comes to SEO, there are two main challenges related to the use of JavaScript:
- Crawling obstacles. Reminder: If a page isn’t indexed, it won’t appear in search results (SERPs), meaning it won’t generate organic traffic.
- Page load time, visual stability, and time to interactivity. Reminder: Core Web Vitals can affect both a site’s ranking and user experience.
This article focuses on the first challenge: crawling obstacles. Indexing is a crucial prerequisite for organic traffic. If a page cannot be indexed, its Lighthouse score or Core Web Vitals performance is irrelevant. Without indexing, there will be no impact on the site’s ranking.
JavaScript makes for Interactive Websites (Interactive UI)
JavaScript is one of the core technologies of the web. While HTML provides the structure and CSS handles the styling, JavaScript brings dynamic elements to life, such as dropdown menus, form validation, clickable tiles, accordion-style FAQs, and more.
Unlike server-side languages like Java or PHP, JavaScript runs directly in the user’s browser, interacting with the web page in real time. When it comes to interactive design and interactive user interfaces, it’s almost guaranteed that the front-end will rely on JavaScript.
How does Google execute JavaScript?
Google processes JavaScript-based web applications in three main phases:
- Crawling
- Rendering
- Indexing
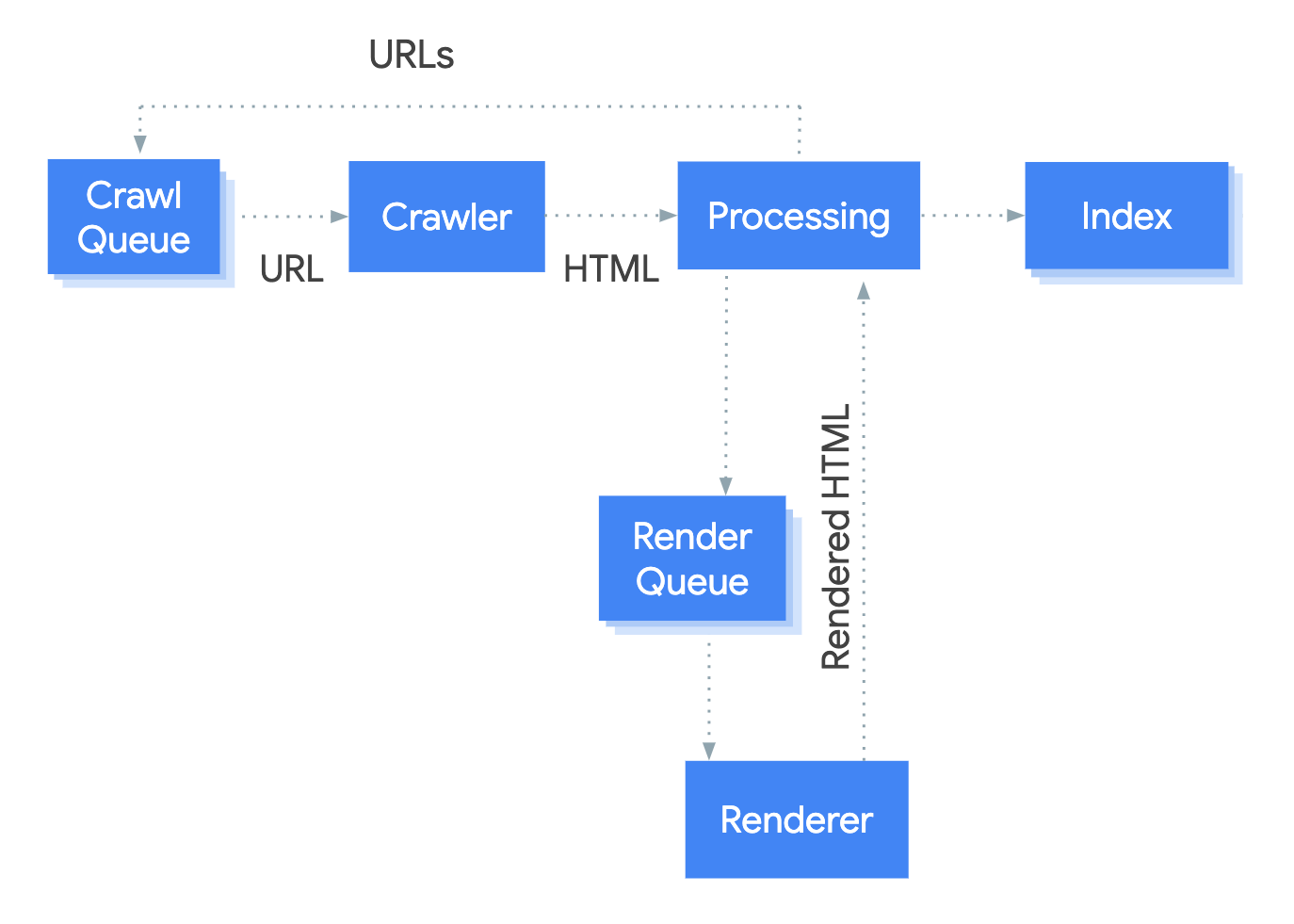
Googlebot queues pages for both crawling and rendering. This means that a page can be in one of two states:
- Waiting to be crawled
- Waiting to be rendered
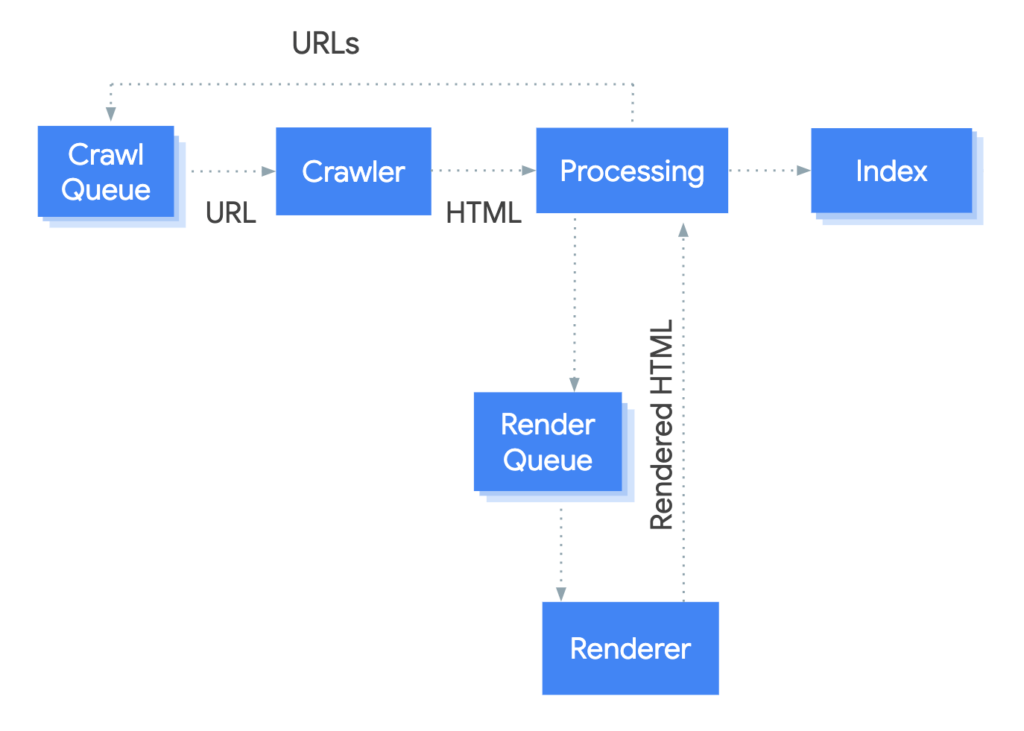
Credit Picture: Google Developers
{kind=link}
The crawling-rendering process is essential for all websites and new pages. It is the SEO specialist’s responsibility to ensure that critical content is understood by Google Bots. However, achieving this requires collaboration with both the development and design teams.
“Pretty much every website when we see them for the first time goes to rendering, so there’s no indexing before it hasn’t been rendered.”
Impact of robots.txt and nofollow attributes on the indexing process
Google’s crawlers extract a URL from the crawling queue via an HTTP request and check whether the website allows crawling. If the robots.txt file, located at the root of the website, blocks crawling, Googlebot does not send the HTTP request for that URL and simply ignores it. It is possible to block crawling for one or more crawlers, either for the entire site or for specific sections of it.
After verifying the crawling permission through the robots.txt file, Googlebot processes the response and analyses the other URLs included in the page’s HTML links (href attributes), then adds those URLs to the crawling queue. To prevent links on a page from being discovered, the nofollow attribute must be used. Google’s crawlers are often compared to spiders that discover the web by following links from one page to another.
Crawling a URL and analysing the HTML response works well for traditional websites or server-side rendered pages, where the entire content is included in the HTML response. However, some JavaScript-based websites use a model where the initial HTML code does not contain the actual content of the site. In this case, Google needs to execute the JavaScript to access the page’s content or sections generated by JavaScript. Google then compares the initial server response with the rendered page to understand the final content.
The rendering queue can be long
Googlebot places all pages in a rendering queue unless a header or meta robots tag instructs it not to index the page. A page can remain in this queue for a few seconds or much longer. Once Google’s resources allow it, the JavaScript code is executed. After rendering, Google continues the process: the links found in the rendered HTML are added to the crawling queue. Google also uses the rendered HTML to index the page.
Googlebot caches content aggressively to reduce network requests and resource usage. The Web Rendering Service (WRS) can ignore cache headers (source: Resolving JavaScript Issues in Search). If Google deems certain content non-essential, it may choose not to retrieve those resources.
Rendering options
Choosing between client-side rendering and server-side rendering is a key decision in search engine optimisation, and I recommend making this choice only after evaluating the potential negative impact.
If you are reading this article and working in a web development team, you know that rendering is far from straightforward. For those who may not yet have experience beyond server-side rendering (SSR), client-side rendering (CSR), and static rendering, there are a variety of rendering options to explore.

Credit Picture: Gray Dot Company training with Sitebulb and Women in Tech SEO
Learn more about CSSOM and DOM trees, which combine to form the render tree, on web.dev.
Overall, SSR often costs more to implement than CSR, which explains the prevalence of client-side rendering.
The best solution for crawlers: server-side rendering
According to Google’s documentation, the rendering method chosen does not directly impact rankings, provided certain guidelines are followed. However, Google states a preference for server-side rendering (SSR) or pre-rendering, as it allows both users and crawlers to access your site more quickly.
SEO challenge
From an SEO perspective, the main challenge lies in the difference between content before and after rendering. Content that is not accessible or visible before rendering — meaning before a user action such as a click — could be considered hidden by both users and crawlers. Making critical content available only after executing JavaScript complicates access to that information and may disrupt the discovery process, potentially limiting optimal indexing.
SEO Consultant’s Recommendation on Using JavaScript
This article aims to help you take a critical approach to the use of JavaScript and evaluate its pros and cons. My goal is not to convince you to stop using JavaScript altogether. However, I strongly recommend avoiding the use of JavaScript for critical information.
“Googlebot et son composant Web Rendering Service (WRS) analysent et identifient en permanence les ressources qui ne contribuent pas au contenu essentiel de la page et peuvent choisir de ne pas récupérer ces ressources.”
I can’t stress this enough: choose carefully which information you display using JavaScript and how you implement it. Not all information holds the same value in terms of SEO. Your primary focus should be on critical information, followed by less critical details.
Note: The summary of critical information is based on the training provided by Gray Dot, Sitebulb, and WTS, which are referenced below.
Critical Fields
Language variations should not be managed via JavaScript but should have dedicated URLs.
In terms of content, the critical elements are:
- Title
- Metadescription (if used)
- Meta robots
- Canonical tag
Other important elements include:
- Navigation links (menu links)
- Pagination links
- Headings (H1, H2, H3, etc.)
The “nice-to-have” critical elements are:
- Page copy (textual content of the page)
- Links within the content (anchor texts)
- Informative images and their alt text (excluding decorative images).
Less Critical Fields
In terms of content, the following fields are considered less critical:
- Duplicate content
- Content overly focused on the brand (not desired or effective for SEO)
In terms of links, the following fields are less critical:
- Links to pages with restricted access
- Links to non-indexable pages
In terms of media, the following fields are less critical:
Decorative images
- Images, videos, and other media that are not essential to the page content
If a field I consider less critical is not discovered by crawlers, I won’t prioritise activities related to optimising it in the SEO strategy.
What Are the Signs of JavaScript Issues?
The following issues may indicate problems with JavaScript (non-exhaustive list):
- Only part of the page or content is crawled or indexed
- Images are not indexed
- Critical errors prevent crawling or rendering, such as timeouts or broken scripts
- Critical SEO elements are missing from the initial HTML response for first-wave indexing
- Metadata is missing
- Critical SEO elements are modified between the initial response and the rendered HTML
- 404 pages are not working correctly, or unexpected soft 404 errors occur
- Unwanted URLs are indexed (e.g., orphan construction pages)
Note: When I have time, I’ll write a guide on how to discover and debug JavaScript issues 🙂 In the meantime, check the list of sources in this article for useful training materials. especially the ones from Gray Dot Company.
Conclusion
It’s likely that more technical experts will read this and say, “There’s no problem with CSR as long as you implement {insert complicated workaround here}!” I get it. You can make CSR work.
However, making something work is very different from operating within a JavaScript framework that has minimal dependencies and technical risks. Especially when SEO is responsible for generating the majority of new business, SSR remains the least risky and most profitable option, in my professional opinion.
References and sources for this article
To deepen my knowledge of JavaScript, I’ve read numerous articles and taken online courses. I would like to thank the authors who created them. Below is a list of the articles and courses that I used as sources for this post. I highly recommend consulting them for further learning.
AHA! JavaScript SEO Moments: 8 Common JS SEO Issues & How to Overcome Them (Gray Dot Company, 2023)
Free JavaScript SEO Course: On-Demand Training, (Sitebulb, Women in Tech SEO, Gray Dot Company, 2024)
Understanding the JavaScript SEO basics (Google, documentation)
The new evergreen Googlebot (Google, 2019)
The new evergreen Bingbot simplifying SEO by leveraging Microsoft Edge (Bing, 2019)
Evaluating page experience for a better web (Google,2020)
Google Webmaster Central office – hours (Google, 2019)